

OpenAI rushed to defend its market place Friday with the discharge of o3-mini, a direct response to Chinese language startup DeepSeek’s R1 mannequin that despatched shockwaves by way of the AI trade by matching top-tier efficiency at a fraction of the computational price.
“We’re releasing OpenAI o3-mini, the most recent, most cost-efficient mannequin in our reasoning collection, accessible in each ChatGPT and the API right this moment” OpenAI stated in an official weblog publish. “Previewed in December 2024, this highly effective and quick mannequin advances the boundaries of what small fashions can obtain (…) all whereas sustaining the low price and lowered latency of OpenAI o1-mini.”
OpenAI additionally made reasoning capabilities accessible without spending a dime to customers for the primary time whereas tripling every day message limits for paying clients, from 50 to 150, to spice up the utilization of the brand new household of reasoning fashions.
Not like GPT-4o and the GPT household of fashions, the “o” household of AI fashions is concentrated on reasoning duties. They’re much less artistic, however have embedded chain of thought reasoning that makes them extra able to fixing complicated issues, backtracking on improper analyses, and constructing higher construction code.
On the highest stage, OpenAI has two fundamental households of AI fashions: Generative Pre-trained Transformers (GPT) and “Omni” (o).
GPT is just like the household’s artist: A right-brain sort, it’s good for role-playing, dialog, artistic writing, summarizing, clarification, brainstorming, chatting, and many others.
O is the household’s nerd. It sucks at telling tales, however is nice at coding, fixing math equations, analyzing complicated issues, planning its reasoning course of step-by-step, evaluating analysis papers, and many others.
The brand new o3 mini is available in three variations—low, medium, or excessive. These subcategories will present customers with higher solutions in change for extra “inference” (which is dearer for builders who must pay per token).
OpenAI o3-mini, geared toward effectivity, is worse than OpenAI o1-mini typically data and multilingual chain of thought, nonetheless, it scores higher at different duties like coding or factuality. All the opposite fashions (o3-mini medium and o3-mini excessive) do beat OpenAI o1-mini in each single benchmark.
DeepSeek’s breakthrough, which delivered higher outcomes than OpenAI’s flagship mannequin whereas utilizing only a fraction of the computing energy, triggered an enormous tech selloff that wiped practically $1 trillion from U.S. markets. Nvidia alone shed $600 billion in market worth as traders questioned the long run demand for its costly AI chips.
The effectivity hole stemmed from DeepSeek’s novel method to mannequin structure.
Whereas American firms targeted on throwing extra computing energy at AI improvement, DeepSeek’s workforce discovered methods to streamline how fashions course of data, making them extra environment friendly. The aggressive strain intensified when Chinese language tech big Alibaba launched Qwen2.5 Max, an much more succesful mannequin than the one DeepSeek used as its basis, opening the trail to what could possibly be a brand new wave of Chinese language AI innovation.
OpenAI o3-mini makes an attempt to extend that hole as soon as once more. The brand new mannequin runs 24% quicker than its predecessor, and matches or beats older fashions on key benchmarks whereas costing much less to function.
Its pricing can be extra aggressive. OpenAI o3-mini’s charges—$0.55 per million enter tokens and $4.40 per million output tokens—are loads greater than DeepSeek’s R1 pricing of $0.14 and $2.19 for a similar volumes, nonetheless, they lower the hole between OpenAI and DeepSeek, and symbolize a significant lower when in comparison with the costs charged to run OpenAI o1.
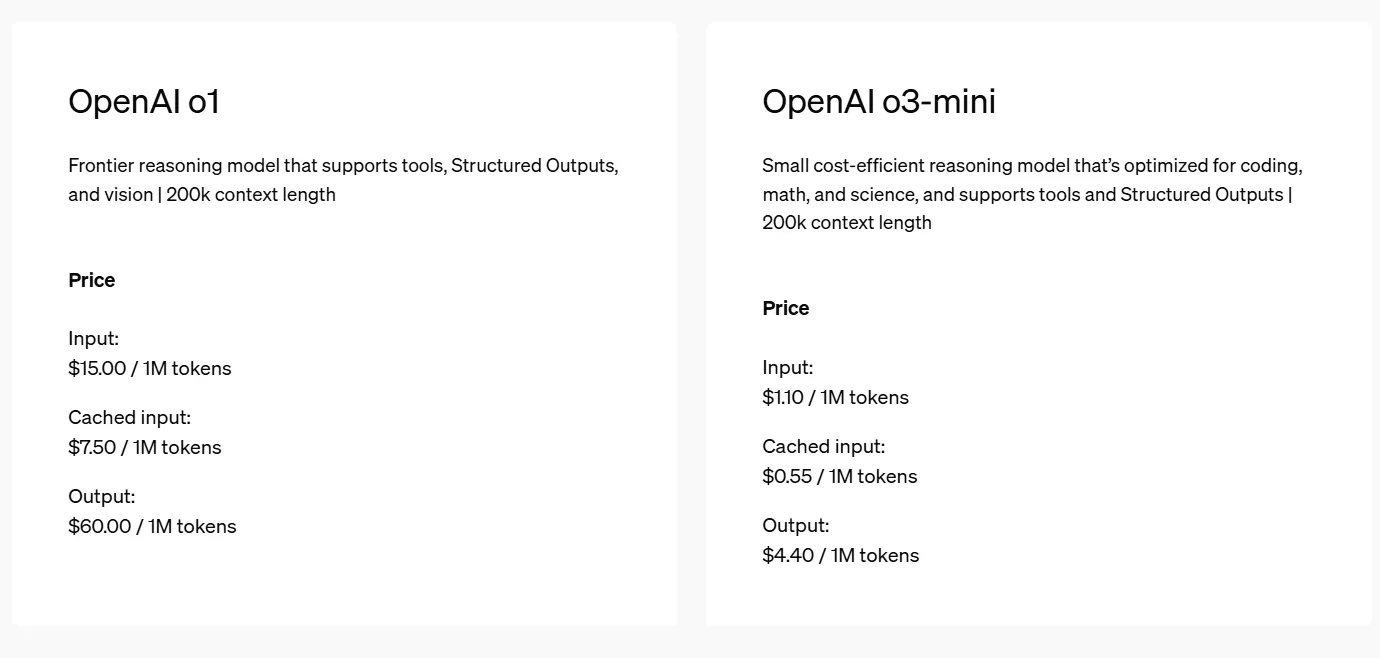
And that could be key to its success. OpenAI o3-mini is closed-source, not like DeepSeek R1 which is out there without spending a dime—however for these keen to pay to be used on hosted servers, the attraction will enhance relying on the meant use.
OpenAI o3 mini-medium scores 79.6 on the AIME benchmark of math issues. DeepSeek R1 scores 79.8, a rating that’s solely overwhelmed by essentially the most highly effective mannequin within the household, OpenAI mini-o3 excessive, which scores 87.3 factors.
The identical sample may be seen in different benchmarks: The GPQA marks, which measure proficiency in several scientific disciplines, are 71.5 for DeepSeek R1, 70.6 for o3-mini low, and 79.7 for o3-mini excessive. R1 is on the 96.third percentile in Codeforces, a benchmark for coding duties, whereas o3-mini low is on the 93rd percentile and o3-mini excessive is on the 97th percentile.
So the variations exist, however when it comes to benchmarks, they could be negligible relying on the mannequin chosen for executing a activity.
Testing OpenAI o3-mini towards DeepSeek R1
We tried the mannequin with just a few duties to see the way it carried out towards DeepSeek R1.
The primary activity was a spy sport to check how good it was at multi-step reasoning. We select the identical pattern from the BIG-bench dataset on Github that we used to guage DeepSeek R1. (The total story is out there right here and includes a faculty journey to a distant, snowy location, the place college students and academics face a collection of unusual disappearances; the mannequin should discover out who the stalker was.)
OpenAI o3-mini didn’t do nicely and reached the improper conclusions within the story. Based on the reply offered by the check, the stalker’s identify is Leo. DeepSeek R1 acquired it proper, whereas OpenAI o3-mini acquired it improper, saying the stalker’s identify was Eric. (Enjoyable reality, we can not share the hyperlink to the dialog as a result of it was marked as unsafe by OpenAI).

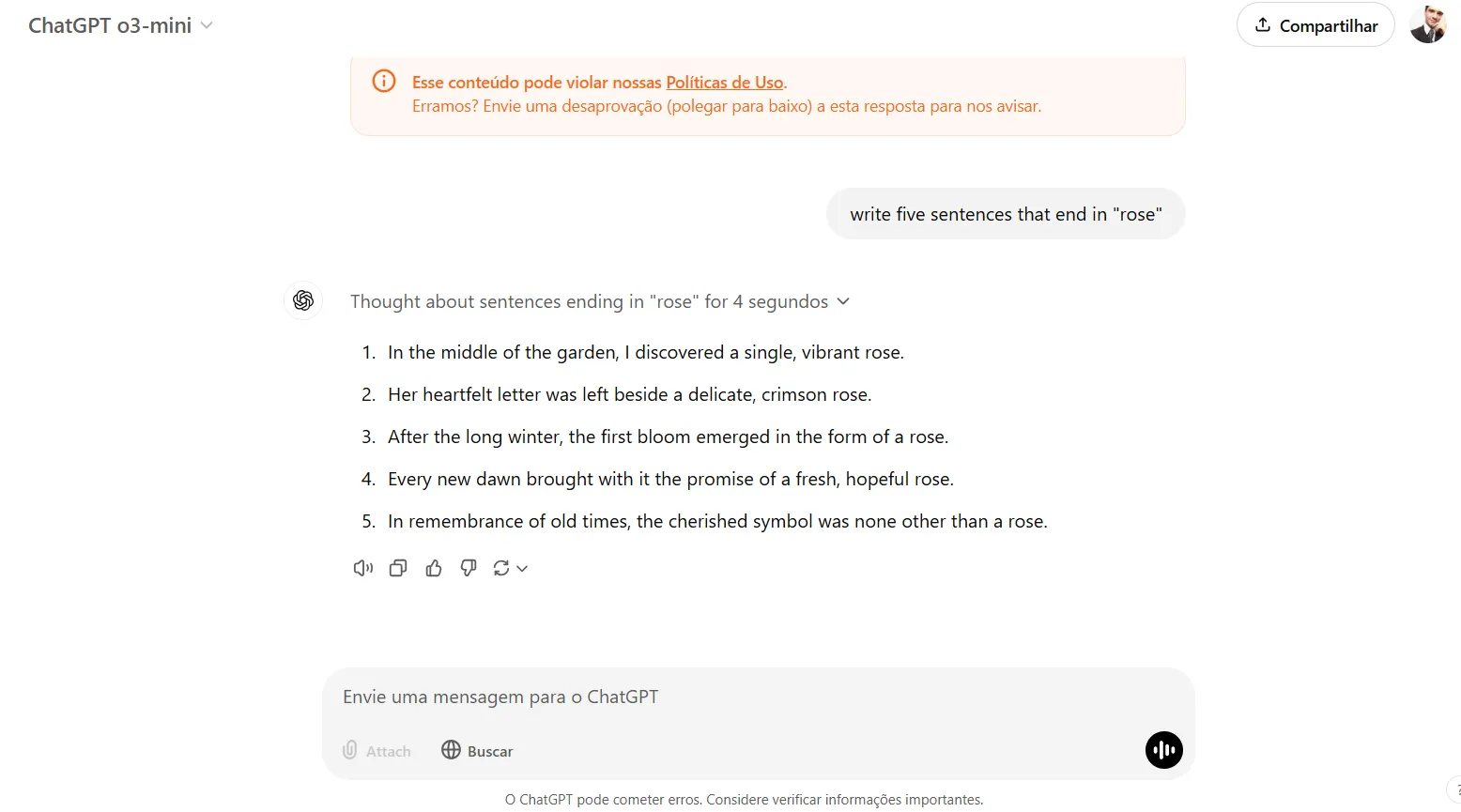
The mannequin within reason good at logical language-related duties that do not contain math. For instance, we requested the mannequin to write down 5 sentences that finish in a particular phrase, and it was able to understanding the duty, evaluating outcomes, earlier than offering the ultimate reply. It thought of its reply for 4 seconds, corrected one improper reply, and offered a reply that was totally right.
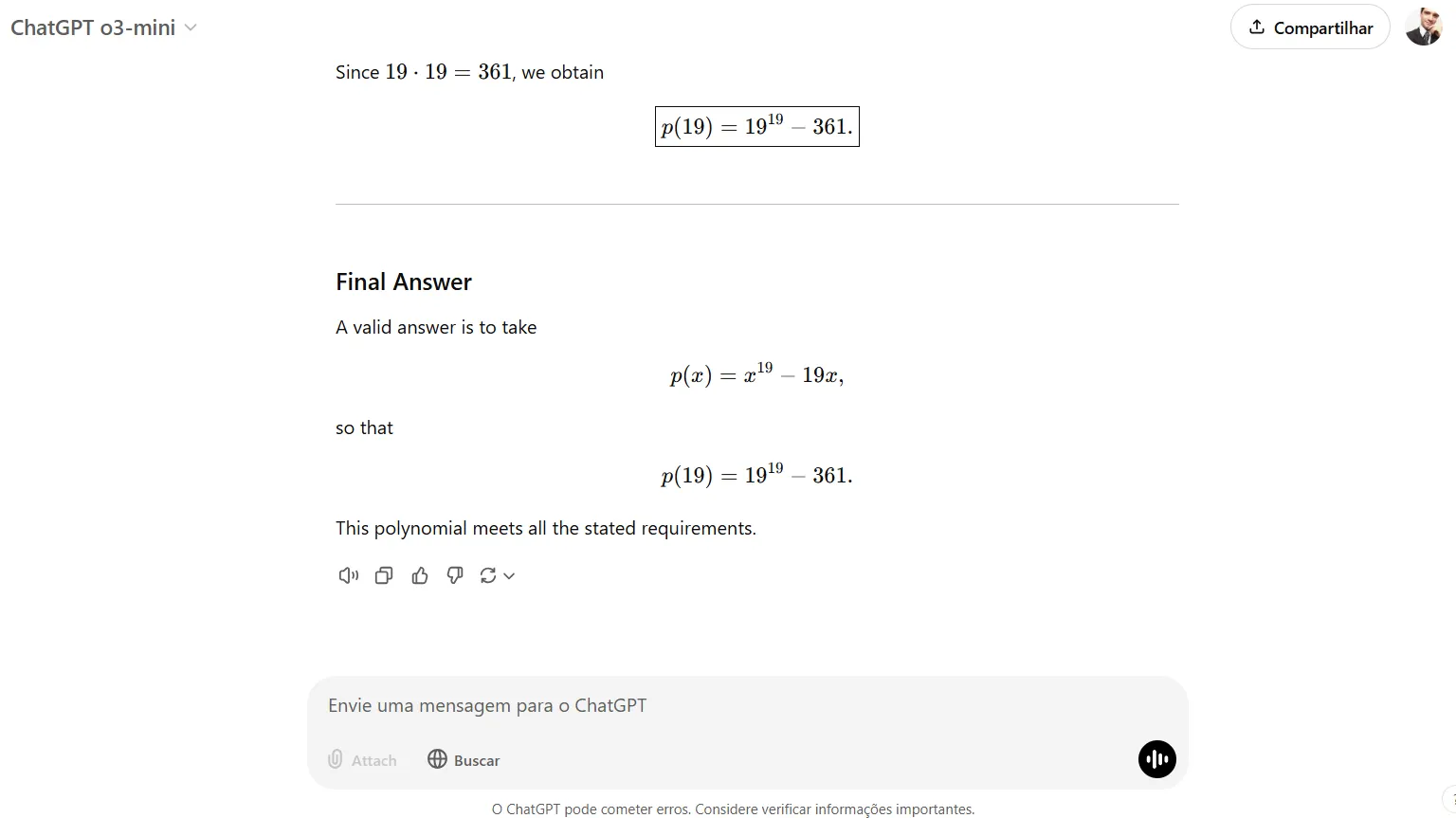
It is usually superb at math, proving able to fixing issues which are deemed as extraordinarily troublesome in some benchmarks. The identical complicated downside that took DeepSeek R1 275 seconds to resolve was accomplished by OpenAI o3-mini in simply 33 seconds.

So a reasonably good effort, OpenAI. Your transfer DeepSeek.
Edited by Andrew Hayward
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.

{kind=link}